尽管人工智能和机器学习应用的加速仍是一个相对较新的领域,但各种处理器如雨后春笋般涌现,几乎可以加速任何神经网络工作负载。
EETimes,从垂直市场、应用领域、功率预算及价格多个方面对目前市场上的应用处理器进行了盘点。
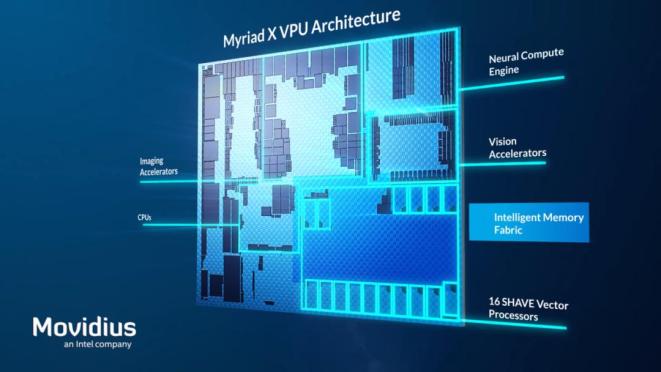
Intel Movidius Myriad X
Myriad X由爱尔兰初创公司Movidius开发,该公司于2016年被英特尔收购。
Myriad X是该公司的第三代视觉处理单元,也是首款搭载专用神经网络计算引擎的产品,可提供每秒1兆次的专用深度神经网络(DNN)计算,可提供1兆次的运算能力。
神经计算引擎直接与高通量智能内存架构对接,避免了数据传输时的内存瓶颈。它支持FP16和INT8计算。Myriad X还拥有16个专有的SHAVE内核集群和升级扩展的视觉加速器。
Myriad X采用了英特尔的Neural Compute Stick 2,实际上就是一个U盘形式的评估平台。它可以插在任何工作站上,让AI和计算机视觉应用很快就能在Movidius的专用硬件上启动并运行。
恩智浦半导体i.MX 8M Plus
i.MX 8M Plus是一款异构应用处理器,采用了芯原公司的专用神经网络加速器IP(Vivante VIP8000)。

除了神经网络处理器外,i.MX 8M Plus还搭载了运行在2GHz的四核Arm Cortex-A53子系统,外加Cortex-M7实时子系统。
视觉应用方面,有两个图像信号处理器,支持两个高清摄像头,可实现立体视觉,也可支持单个1200万像素(MP)摄像头。
在语音方面,该设备包括一个800MHz的HiFi4音频数字信号处理器(DSP),用于语音数据的前、后处理。
XMOS的xcore.ai
xcore.ai旨在实现人工智能物联网(AIoT)应用中的语音控制。这款设备是一个交叉处理器(具有应用处理器的性能和微控制器的低功耗、实时操作),专门用于对语音信号进行机器学习推理。

将不同的功能映射到固件中的逻辑内核,可以创建一个完全由软件编写的 "虚拟SoC"。XMOS为Xcore增加了向量管道功能,用于机器学习工作负载。
xcore.ai支持32位、16位、8位和1位(二值化)网络,可提供3200 MIPS、51.2 GMACC和1600 MFLOPS。它拥有1 Mbyte的嵌入式SRAM和低功耗DDR接口,可用于扩展。
德州仪器公司 TDA4VM
作为Jacinto 7系列汽车高级驾驶辅助系统(ADAS)的一部分,TDA4VM是TI首款具有专用深度学习加速器的片上系统(SoC)。

该SoC可以处理来自前置摄像头的视频流,最高可达8MP,或者是4到6个3MP摄像头加上雷达、LiDAR和超声波传感器的组合。
例如,在自动泊车系统中,MMA可能用于对这些输入进行传感器融合。
TDA4VM是为5到20W之间的ADAS设计而设计的。
Nvidia的Jetson Nano
Nvidia著名的Jetson Nano是一款小巧但功能强大的图形处理单元(GPU)模块,用于终端设备中的AI应用。

使用时,它的功耗低至5W。该模块还采用了四核Arm Cortex-A57 CPU。
与Nvidia的其他部件一样,Jetson Nano也使用了Nvidia的神经网络加速库CUDA X。价格不贵的Jetson Nano开发套件已被广泛使用。
Kneron Inc. KL520
中国台湾初创公司Kneron的首款产品是KL520神经网络处理器,是专为智能家居、安防系统和移动设备等应用中的图像处理和面部识别而设计的。它可以运行卷积神经网络(CNNs),是目前图像处理中常用的类型。
KL520可运行0.3 TOPS,功耗为0.5 W(相当于0.6 TOPS/W),该公司表示,鉴于该芯片的MAC效率很高(超过90%),这足以实现准确的面部识别。
该芯片的架构是可重新配置的,可以根据不同的CNN模型进行定制。该公司的辅助编译器还采用了压缩技术,以便在芯片资源内运行更大的模型,以节省功耗和成本。目前KL520已经上市,也可以在厂商AAEON的加速器卡上找到(M2AI-2280-520)。
Gyrfalcon Lightspeeur 5801
Gyrfalcon的Lightspeeur 5801专为消费类电子市场设计,在224mW的功耗下提供2.8 TOPS(相当于12.6 TOPS/W),延迟为4ms。Gyrfalcon使用了一种处理器内存储器技术,与其他架构相比,该技术特别省电。
功耗实际上可以通过改变50到200MHz之间的时钟速度来抵消功耗。Lightspeeur 5801包含10MB的内存,因此整个型号可以装在芯片上。
该部分是该公司的第四款量产芯片,已经出现在LG的Q70中端智能手机上,它处理相机效果的推理。现在已经推出了一款USB优盘开发套件,即5801 Plai Plug,目前已经上市。
Eta Compute的ECM3532
Eta Compute的首款量产产品ECM3532是专为IoT的电池供电或能量收集设计中的AI加速而设计的。在图像处理和传感器融合方面的始终开机应用,只需低至100微瓦的功率预算就能实现。
该芯片有两个内核--一个Arm Cortex-M3微控制器内核和一个NXP CoolFlux DSP。该公司使用了一种专有的电压和频率缩放技术,在每一个时钟周期内进行调整,以榨取两个内核的每一滴电能。
机器学习工作负载可由两个内核中的任何一个内核处理(例如,某些语音工作负载更适合DSP)。ECM3532的样品现已上市,预计第二季度开始量产。
Syntiant公司NDP100
美国初创公司Syntiant公司的NDP100处理器是专为在电力紧张的应用中对语音指令进行机器学习推理而设计的。其基于内存中处理器的芯片功耗不到140微瓦,可运行关键词识别、唤醒词检测、语音识别或事件分类等模型。
Syntiant表示,该产品将用于实现消费类设备的免提操作,如耳机、助听器、智能手表和遥控器等。开发套件现已推出。
GreenWaves Technologies GAP9
GAP9是法国初创公司GreenWaves公司推出的首款超低功耗应用处理器,它拥有强大的计算集群,由9个RISC-V内核组成,其指令集经过大量定制,以优化功耗。它具有双向多通道音频接口和1.6MB的内部RAM。
GAP9可以处理电池供电的IoT设备中的图像、声音和振动感应的神经网络工作负载。GreenWaves的数据显示,GAP9在160×160的图像上运行MobileNet V1,通道缩放为0.25,仅需12毫秒,功耗为806μW/帧/秒。
参考链接:
https://www.eetimes.eu/top-10-processors-for-ai-acceleration-at-the-endpoint/
来源:新智元
图文系网络转载,版权归原作者所有。不代表本公众号观点,如涉及作品版权问题,请与我们联系,我们将在第一时间协商版权问题或删除内容!
原标题:《2020最强终端AI加速芯片Top10排行榜》



